
GATE CSE Computer Organization PYQ
| Q1➡ | GATE 2021 Set-1 Consider a computer system with a byte-addressable primary memory of size 232bytes. Assume the computer system has a direct-mapped cache of size 32 KB (1 KB = 210bytes), and each cache block is of size 64 bytes. The size of the tag field is __ bits. |
Show Answer With Best Explanation
Answer: 17
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Cache | Help-Line |
| Q2➡ | GATE 2021 Set-1 Consider the following instruction sequence where registers R1, R2 and R3 are general purpose and MEMORY[X] denotes the content at the memory location X.  Assume that the content of the memory location 5000 is 10, and the content of the register R3 is 3000. The content of each of the memory locations from 3000 to 3010 is 50. The instruction sequence starts from the memory location 1000. All the numbers are in decimal format. Assume that the memory is byte addressable. After the execution of the program, the content of memory location 3010 is _ |

Show Answer With Best Explanation
Answer: 50
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Machine Instructions | Help-Line |
| Q3➡ | GATE 2021 Set-1 A five-stage pipeline has stage delays of 150, 120, 150, 160 and 140 nanoseconds. The registers that are used between the pipeline stages have a delay of 5 nanoseconds each. The total time to execute 100 independent instructions on this pipeline, assuming there are no pipeline stalls, is ___ nanoseconds. |
Show Answer With Best Explanation
Answer: 17160
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Pipelinig | Help-Line |
| Q4➡ | GATE 2021 Set-2 Assume a two-level inclusive cache hierarchy, L1 and L2, where L2 is the larger of the two. Consider the following statements. S1: Read misses in a write through L1 cache do not result in writebacks of dirty lines to the L2. S2: Write allocate policy must be used in conjunction with write through caches and no-write allocate policy is used with write back caches. |
| i ➥ S1 is false and S2 is true |
| ii ➥ S1 is true and S2 is false |
| iii ➥ S1 is false and S2 is false |
| iv ➥ S1 is true and S2 is true |
Show Answer With Best Explanation
Answer: II
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Cache Hierarchy | Help-Line |
| Q5➡ | GATE 2021 Set-2 Consider a computer system with DMA support, The DMA module is transferring one 8-bit character in one CPU cycle from a device to memory through cycle stealing at regular intervals. Consider a 2 MHz processor. If 0.5% processor cycles are used for DMA, the data transfer rate of the device is ________ bits per second. |
Show Answer With Best Explanation
Answer: 80,000
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | DMA | Help-Line |
| Q6➡ | GATE 2021 Set-2 Consider a set-associative cache of size 2KB (1KB = 210bytes) with cache block size of 64 bytes. Assume that the cache is byte-addressable and a 32-bit address is used for accessing the cache. If the width of the tag field is 22 bits, the associativity of the cache is __ |
Show Answer With Best Explanation
Answer: 2
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Mapping | Help-Line |
| Q7➡ | GATE 2021 Set-2 Consider a pipelined processor with 5 stages, Instruction Fetch (IF), Instruction Decode (ID), Execute (EX), Memory Access (MEM), and Write Back (WB). Each stage of the pipeline, except the EX stage, takes one cycle. Assume that the ID stage merely decodes the instruction and the register read is performed in the EX stage. The EX stage takes one cycle for ADD instruction and two cycles for MUL instruction. Consider the following sequence of 8 instructions: ADD, MUL, ADD, MUL, ADD, MUL, ADD, MUL Assume that every MUL instruction is data-dependent on the ADD instruction just before it and every ADD instruction (except the first ADD) is data- dependent on the MUL instruction just before it. The Speedup is defined as follows:  |

Show Answer With Best Explanation
Answer: 1.87 to 1.88
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Pipeline | Help-Line |
| Q8➡ | GATE 2020 Consider the following data path diagram: 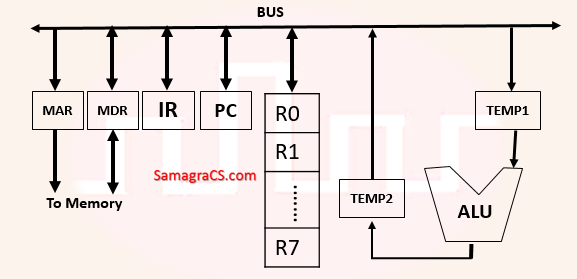 Consider an instruction: R0 ← R1 + R2. The following steps are used to execute it over the given data path. Assume that PC is incremented appropriately. The subscripts r and w indicate read and write operations, respectively. 1. R2r, TEMP1r, ALUadd, TEMP2w 2. R1r, TEMP1w 3. PCr, MARw, MEMr 4. TEMP2r, ROw 5. MDRr, IRw Which one of the following is the correct order of execution of the above steps? |

| i ➥ 2, 1, 4, 5, 3 |
| ii ➥ 1, 2, 4, 3, 5 |
| iii ➥ 3, 5, 1, 2, 4 |
| iv ➥ 3, 5, 2, 1, 4 |
Show Answer With Best Explanation
Answer: IV
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Registers | Help-Line |
| Q9➡ | GATE 2020 Consider the following statements. I. Daisy chaining is used to assign priorities in attending interrupts. II. When a device raises a vectored interrupt, the CPU does polling to identify the source of the interrupt. III. In polling, the CPU periodically checks the status bits to know if any device needs its attention. IV. During DMA, both the CPU and DMA controller can be bus masters at the same time. Which of the above statements is/are TRUE? |
| i ➥ I and III only |
| ii ➥ I and IV only |
| iii ➥ I and II only |
| iv ➥ III only |
Show Answer With Best Explanation
Answer: I
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Interrupt | Help-Line |
| Q10➡ | GATE 2020 A computer system with a word length of 32 bits has a 16 MB byte-addressable main memory and a 64 KB, 4-way set associative cache memory with a block size of 256 bytes. Consider the following four physical addresses represented in hexadecimal notation. A1 = 0x42C8A4, A2 = 0x546888, A3 = 0x6A289C, A4 = 0x5E4880 Which one of the following is TRUE? |
| i ➥ A3 and A4 are mapped to the same cache set. |
| ii ➥ A1 and A4 are mapped to different cache sets. |
| iii ➥ A2 and A3 are mapped to the same cache set. |
| iv ➥ A1 and A3 are mapped to the same cache set. |
Show Answer With Best Explanation
Answer: III
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Cache | Help-Line |
| Q11➡ | GATE 2020 A processor has 64 registers and uses 16-bit instruction format. It has two types of instructions: I-type and R-type. Each I-type instruction contains an opcode, a register name, and a 4-bit immediate value. Each R-type instruction contains an opcode and two register names. If there are 8 distinct I-type opcodes, then the maximum number of distinct R-type opcodes is ___________. |
Show Answer With Best Explanation
Answer: 14
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Registers | Help-Line |
| Q12➡ | GATE 2020 Consider a non-pipelined processor operating at 2.5 GHz. It takes 5 clock cycles to complete an instruction. You are going to make a 5-stage pipeline out of this processor. Overheads associated with pipelining force you to operate the pipelined processor at 2 GHz. In a given program, assume that 30% are memory instructions, 60% are ALU instructions and the rest are branch instructions. 5% of the memory instructions cause stalls of 50 clock cycles each due to cache misses and 50% of the branch instructions cause stalls of 2 cycles each. Assume that there are no stalls associated with the execution of ALU instructions. For this program, the speedup achieved by the pipelined processor over the non-pipelined processor (round off to 2 decimal places) is ________. |
Show Answer With Best Explanation
Answer: 2.15 to 2.18
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Pipeling | Help-Line |
| Q13➡ | GATE 2019 The chip select logic for a certain DRAM chip in a memory system design is shown below. Assume that the memory system has 16 address lines denoted by A15 to A0. What is the range of addresses (in hexadecimal) of the memory system that can get enabled by the chip select (CS) signal? 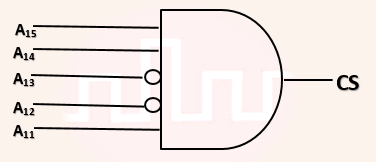 |

| i ➥ C800 to CFFF |
| ii ➥ DA00 to DFFF |
| iii ➥ CA00 to CAFF |
| iv ➥ C800 to C8FF |
Show Answer With Best Explanation
Answer: I
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | DRAM | Help-Line |
| Q14➡ | GATE 2019 A certain processor uses a fully associative cache of size 16 kB. The cache block size is 16 bytes. Assume that the main memory is byte addressable and uses a 32-bit address. How many bits are required for the Tag and the Index fields respectively in the addresses generated by the processor? |
| i ➥ 28 bits and 4 bits |
| ii ➥ 28 bits and 0 bits |
| iii ➥ 24 bits and 4 bits |
| iv ➥ 24 bits and 0 bits |
Show Answer With Best Explanation
Answer: II
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Cache | Help-Line |
| Q15➡ | GATE 2019 A certain processor deploys a single-level cache. The cache block size is 8 words and the word size is 4 bytes. The memory system uses a 60-MHz clock. To service a cache miss, the memory controller first takes 1 cycle to accept the starting address of the block, it then takes 3 cycles to fetch all the eight words of the block, and finally transmits the words of the requested block at the rate of 1 word per cycle. The maximum bandwidth for the memory system when the program running on the processor issues a series of read operations is _________ × 106 bytes/sec. |
Show Answer With Best Explanation
Answer: 160
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Cache | Help-Line |
| Q16➡ | GATE 2018 Consider the following processor design characteristics. I. Register-to-register arithmetic operations only II. Fixed-length instruction format III. Hardwired control unit Which of the characteristics above are used in the design of a RISC processor? |
| i ➥ I and III only |
| ii ➥ I, II and III |
| iii ➥ I and II only |
| iv ➥ II and III only |
Show Answer With Best Explanation
Answer: II
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | RISC | Help-Line |
| Q17➡ | GATE 2018 The following are some events that occur after a device controller issues an interrupt while process L is under execution. (P) The processor pushes the process status of L onto the control stack. (Q)The processor finishes the execution of the current instruction. (R) The processor executes the interrupt service routine. (S) The processor pops the process status of L from the control stack. (T) The processor loads the new PC value based on the interrupt. Which one of the following is the correct order in which the events above occur? |
| i ➥ QTPRS |
| ii ➥ TRPQS |
| iii ➥ PTRSQ |
| iv ➥ QPTRS |
Show Answer With Best Explanation
Answer: IV
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | interrupt | Help-Line |
| Q18➡ | GATE 2018 Consider a process executing on an operating system that uses demand paging. The average time for a memory access in the system is M units if the corresponding memory page is available in memory, and D units if the memory access causes a page fault. It has been experimentally measured that the average time taken for a memory access in the process is X units. Which one of the following is the correct expression for the page fault rate experienced by the process? |
| i ➥ (D – M) / (X – M) |
| ii ➥ (X – M) / (D – M) |
| iii ➥ (D – X) / (D – M) |
| iv ➥ (X – M) / (D – X) |
Show Answer With Best Explanation
Answer: II
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | paging | Help-Line |
| Q19➡ | GATE 2018 A 32-bit wide main memory unit with a capacity of 1 GB is built using 256M × 4-bit DRAM chips. The number of rows of memory cells in the DRAM chip is 214. The time taken to perform one refresh operation is 50 nanoseconds. The refresh period is 2 milliseconds. The percentage (rounded to the closest integer) of the time available for performing the memory read/write operations in the main memory unit is _. |
Show Answer With Best Explanation
Answer: 59 To 60
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Memory Interfacing | Help-Line |
| Q20➡ | GATE 2018 The size of the physical address space of a processor is 2P bytes. The word length is 2W bytes. The capacity of cache memory is 2N bytes. The size of each cache block is 2M words. For a K-way set-associative cache memory, the length (in number of bits) of the tag field is |
| i ➥ P – N – log2K |
| ii ➥ P – N + log2K |
| iii ➥ P – N – M – W – log2K |
| iv ➥ P – N – M – W + log2K |
Show Answer With Best Explanation
Answer: II
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Cache | Help-Line |
| Q21➡ | GATE 2018 The instruction pipeline of a RISC processor has the following stages: Instruction Fetch (IF), Instruction Decode (ID), Operand Fetch (OF), Perform Operation (PO) and Writeback (WB). The IF, ID, OF and WB stages take 1 clock cycle each for every instruction. Consider a sequence of 100 instructions. In the PO stage, 40 instructions take 3 clock cycles each, 35 instructions take 2 clock cycles each, and the remaining 25 instructions take 1 clock cycle each. Assume that there are no data hazards and no control hazards. The number of clock cycles required for completion of execution of the sequence of instructions is_____. |
Show Answer With Best Explanation
Answer: 219
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Pipeling | Help-Line |
| Q22➡ | GATE 2018 A processor has 16 integer registers (R0, R1, …, R15) and 64 floating point registers (F0, F1, …, F63). It uses a 2-byte instruction format. There are four categories of instructions: Type-1, Type-2, Type-3 and Type-4. Type-1 category consists of four instructions, each with 3 integer register operands (3Rs). Type-2 category consists of eight instructions, each with 2 floating point register operands (2Fs). Type-3 category consists of fourteen instructions, each with one integer register operand and one floating point register operand (1R+1F). Type-4 category consists of N instructions, each with a floating point register operand (1F). The maximum value of N is _________. |
Show Answer With Best Explanation
Answer: 32
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Machine-Instructions | Help-Line |
| Q23➡ | GATE 2017 Set-1 Consider the C struct defined below: 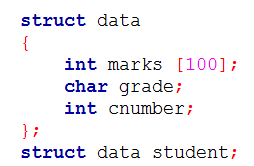 The base address of student is available in register R1. The field student.grade can be accessed efficiently using |

| i ➥ Index addressing mode, X(R1), where X is an offset represented in 2’s complement 16-bit representation |
| ii ➥ Register direct addressing mode, R1 |
| iii ➥ Post-increment addressing mode, (R1)+ |
| iv ➥ Pre-decrement addressing mode, -(R1) |
Show Answer With Best Explanation
Answer: I
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Addressing Modes | Help-Line |
| Q24➡ | GATE 2017 Set-1 Consider a two-level cache hierarchy with L1 and L2 caches. An application incurs 1.4 memory accesses per instruction on average. For this application, the miss rate of L1 cache is 0.1; the L2 cache experiences, on average, 7 misses per 1000 instructions. The miss rate of L2 expressed correct to two decimal places is _______. |
Show Answer With Best Explanation
Answer: 0.05
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Cache | Help-Line |
| Q25➡ | GATE 2017 Set-1 A cache memory unit with capacity of N words and block size of B words is to be designed. If it is designed as a direct mapped cache, the length of the TAG field is 10 bits. If the cache unit is now designed as a 16-way set-associative cache, the length of the TAG field is ________ bits. |
Show Answer With Best Explanation
Answer: 14
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Cache Memory | Help-Line |
| Q26➡ | GATE 2017 Set-1 Consider a 2-way set associative cache with 256 blocks and uses LRU replacement. Initially the cache is empty. Conflict misses are those misses which occur due to contention of multiple blocks for the same cache set. Compulsory misses occur due to first time access to the block. The following sequence of accesses to memory blocks (0, 128, 256, 128, 0, 128, 256, 128, 1, 129, 257, 129, 1, 129, 257, 129) is repeated 10 times. The number of conflict misses experienced by the cache is _________. |
Show Answer With Best Explanation
Answer: 76
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Cache Memory | Help-Line |
| Q27➡ | GATE 2017 Set-1 Instruction execution in a processor is divided into 5 stages, Instruction Fetch (IF), Instruction Decode (ID), Operand Fetch (OF), Execute (EX), and Write Back (WB). These stages take 5, 4, 20, 10 and 3 nanoseconds (ns) respectively. A pipelined implementation of the processor requires buffering between each pair of consecutive stages with a delay of 2 ns. Two pipelined implementations of the processor are contemplated: (i) a naive pipeline implementation (NP) with 5 stages and (ii) an efficient pipeline (EP) where the OF stage is divided into stages OF1 and OF2 with execution times of 12 ns and 8 ns respectively. The speedup (correct to two decimal places) achieved by EP over NP in executing 20 independent instructions with no hazards is _______. |
Show Answer With Best Explanation
Answer: 1.52
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Pipelining | Help-Line |
| Q28➡ | GATE 2017 Set-1 Consider a RISC machine where each instruction is exactly 4 bytes long. Conditional and unconditional branch instructions use PC-relative addressing mode with Offset specified in bytes to the target location of the branch instruction. Further the Offset is always with respect to the address of the next instruction in the program sequence. Consider the following instruction sequence If the target of the branch instruction is i, then the decimal value of the Offset is ________. |
Show Answer With Best Explanation
Answer: -16
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Instruction Cycle | Help-Line |
| Q29➡ | GATE 2017 Set-2 In a two-level cache system, the access times of L1 and L2 caches are 1 and 8 clock cycles, respectively. The miss penalty from the L2 cache to main memory is 18 clock cycles. The miss rate of L1 cache is twice that of L2. The average memory access time (AMAT) of this cache system is 2 cycles. The miss rates of L1 and L2 respectively are: |
| i ➥ 0.111 and 0.056 |
| ii ➥ 0.056 and 0.111 |
| iii ➥ 0.0892 and 0.1784 |
| iv ➥ 0.1784 and 0.0892 |
Show Answer With Best Explanation
Answer: I
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Cache Memory | Help-Line |
| Q30➡ | GATE 2017 Set-2 The read access times and the hit ratios for different caches in a memory hierarchy are as given below: 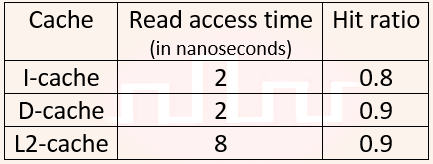 The read access time of main memory is 90 nanoseconds. Assume that the caches use the referred-word-first read policy and the write back policy. Assume that all the caches are direct mapped caches. Assume that the dirty bit is always 0 for all the blocks in the caches. In execution of a program, 60% of memory reads are for instruction fetch and 40% are for memory operand fetch. The average read access time in nanoseconds (up to 2 decimal places) is _________. |

Show Answer With Best Explanation
Answer: 4.72
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Cache Memory | Help-Line |
| Q31➡ | GATE 2017 Set-2 Consider a machine with a byte addressable main memory of 232 bytes divided into blocks of size 32 bytes. Assume that a direct mapped cache having 512 cache lines is used with this machine. The size of the tag field in bits is _______. |
Show Answer With Best Explanation
Answer: 18
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Cache Memory | Help-Line |
| Q32➡ | GATE 2016 Set-1 A processor can support a maximum memory of 4GB, where the memory is word-addressable (a word consists of two bytes). The size of the address bus of the processor is at least ________ bits. |
Show Answer With Best Explanation
Answer: 31
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Memory Interfacing | Help-Line |
| Q33➡ | GATE 2016 Set-1 The size of the data count register of a DMA controller is 16 bits. The processor needs to transfer a file of 29,154 kilobytes from disk to main memory. The memory is byte addressable. The minimum number of times the DMA controller needs to get the control of the system bus from the processor to transfer the file from the disk to main memory is ___________. |
Show Answer With Best Explanation
Answer: 456
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | DMA | Help-Line |
| Q34➡ | GATE 2016 Set-1 The stage delays in a 4-stage pipeline are 800, 500, 400 and 300 picoseconds. The first stage (with delay 800 picoseconds) is replaced with a functionally equivalent design involving two stages with respective delays 600 and 350 picoseconds. The throughput increase of the pipeline is __________percent. |
Show Answer With Best Explanation
Answer: 33 to 34
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Pipelining | Help-Line |
| Q35➡ | GATE 2016 Set-2 A processor has 40 distinct instructions and 24 general purpose registers. A 32-bit instruction word has an opcode, two register operands and an immediate operand. The number of bits available for the immediate operand field is _________. |
Show Answer With Best Explanation
Answer: 16
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Machine Instructions | Help-Line |
| Q36➡ | GATE 2016 Set-2 Suppose the functions F and G can be computed in 5 and 3 nanoseconds by functional units UF and UG, respectively. Given two instances of UF and two instances of UG, it is required to implement the computation F(G(Xi)) for 1 ≤ i ≤ 10. Ignoring all other delays, the minimum time required to complete this computation is _ nanoseconds. |
Show Answer With Best Explanation
Answer: 28
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | CPU Organization | Help-Line |
| Q37➡ | GATE 2016 Set-2 Consider a processor with 64 registers and an instruction set of size twelve. Each instruction has five distinct fields, namely, opcode, two source register identifiers, one destination register r identifier, and a twelve-bit immediate value. Each instruction must be stored in memory in a byte-aligned fashion. If a program has 100 instructions, the amount of memory (in bytes) consumed by the program text is _________. |
Show Answer With Best Explanation
Answer: 500
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Machine Instruction | Help-Line |
| Q38➡ | GATE 2016 Set-2 The width of the physical address on a machine is 40 bits. The width of the tag field in a 512 KB 8-way set associative cache is ________ bits. |
Show Answer With Best Explanation
Answer: 24
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Cache Memory | Help-Line |
| Q39➡ | GATE 2016 Set-2 Consider a 3 GHz (gigahertz) processor with a three-stage pipeline and stage latencies τ1, τ2, τ3 and such that τ1 = 3τ2/4 = 2τ3. If the longest pipeline stage is split into two pipeline stages of equal latency, the new frequency is ____________ GHz, ignoring delays in the pipeline registers |
Show Answer With Best Explanation
Answer: 4
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Pipelining | Help-Line |
| Q40➡ | GATE 2015 Set-1 For computers based on three-address instruction formats, each address field can be used to specify which of the following: (S1) A memory operand (S2) A processor register (S3) An implied accumulator register |
| i ➥ Either S1 or S2 |
| ii ➥ Either S2 or S3 |
| iii ➥ Only S2 and S3 |
| iv ➥ All of S1, S2 and S3 |
Show Answer With Best Explanation
Answer: I
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Machine Instructions | Help-Line |
| Q41➡ | GATE 2015 Set-1 Consider a disk pack with a seek time of 4 milliseconds and rotational speed of 10000 rotations per minute (RPM). It has 600 sectors per track and each sector can store 512 bytes of data. Consider a file stored in the disk. The file contains 2000 sectors. Assume that every sector access necessitates a seek, and the average rotational latency for accessing each sector is half of the time for one complete rotation. The total time (in milliseconds) needed to read the entire file is _________. |
Show Answer With Best Explanation
Answer: 14020
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Secondary Storage | Help-Line |
| Q42➡ | GATE 2015 Set-1 Consider a non-pipelined processor with a clock rate of 2.5 gigahertz and average cycles per instruction of four. The same processor is upgraded to a pipelined processor with five stages; but due to the internal pipeline delay, the clock speed is reduced to 2 gigahertz. Assume that there are no stalls in the pipeline. The speed up achieved in this pipelined processor is _______. |
Show Answer With Best Explanation
Answer: 3.2
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Pipelinig | Help-Line |
| Q43➡ | GATE 2015 Set-2 Assume that for a certain processor, a read request takes 50 nanoseconds on a cache miss and 5 nanoseconds on a cache hit. Suppose while running a program, it was observed that 80% of the processors read requests result in a cache hit. The average and access time in nanoseconds is ________. |
Show Answer With Best Explanation
Answer: 14
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Cache Memory | Help-Line |
| Q44➡ | GATE 2015 Set-2 Consider a typical disk that rotates at 15000 rotations per minute (RPM) and has a transfer rate of 50×106 bytes/sec. If the average seek time of the disk is twice the average rotational delay and the controller’s transfer time is 10 times the disk transfer time, the average time (in milliseconds) to read or write a 512-byte sector of the disk is ________. |
Show Answer With Best Explanation
Answer: 6.1 to 6.2
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Secondary Memory | Help-Line |
| Q45➡ | GATE 2015 Set-2 Consider the sequence of machine instructions given below: MUL R5, R0, R1 DIV R6, R2, R3 ADD R7, R5, R6 SUB R8, R7, R4 In the above sequence, R0 to R8 are general purpose registers. In the instructions shown, the first register stores the result of the operation performed on the second and the third registers. This sequence of instructions is to be executed in a pipelined instruction processor with the following 4 stages: (1) Instruction Fetch and Decode (IF), (2) Operand Fetch (OF), (3) Perform Operation (PO) and (4) Write back the Result (WB). The IF, OF and WB stages take 1 clock cycle each for any instruction. The PO stage takes 1 clock cycle for ADD or SUB instruction, 3 clock cycles for MUL instruction and 5 clock cycles for DIV instruction. The pipelined processor uses operand forwarding from the PO stage to the OF stage. The number of clock cycles taken for the execution of the above sequence of instructions is |
Show Answer With Best Explanation
Answer: 13
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Pipelining | Help-Line |
| Q46➡ | GATE 2015 Set-2 Consider a processor with byte-addressable memory. Assume that all registers, including Program Counter (PC) and Program Status Word (PSW), are of size 2 bytes. A stack in the main memory is implemented from memory location (0100)16 and it grows upward. The stack pointer (SP) points to the top element of the stack. The current value of SP is (016E)16. The CALL instruction is of two words, the first word is the op-code and the second word is the starting address of the subroutine (one word = 2 bytes). The CALL instruction is implemented as follows: • Store the current value of PC in the stack. • Store the value of PSW register in the stack. • Load the starting address of the subroutine in PC. The content of PC just before the fetch of a CALL instruction is (5FA0)16. After execution of the CALL instruction, the value of the stack pointer is |
| i ➥ (016A)16 |
| ii ➥ (016C)16 |
| iii ➥ (0170)16 |
| iv ➥ (0172)16 |
Show Answer With Best Explanation
Answer: IV
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Machine Instruction | Help-Line |
| Q48➡ | GATE 2015 Set-2 A computer system implements a 40-bit virtual address, page size of 8 kilobytes, and a 128-entry translation look-aside buffer (TLB organized into 32 sets each having four ways. Assume that the TLB tag does not store any process id. The minimum length of the TLB tag in bits is _________. |
Show Answer With Best Explanation
Answer: 22
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Virtual Memory | Help-Line |
| Q47➡ | GATE 2015 Set-3 Consider a machine with a byte addressable main memory of 220 bytes, block size of 16 bytes and a direct mapped cache having 212 cache lines. Let the addresses of two consecutive bytes in main memory be (E201F)16 and (E2020)16. What are the tag and cache line address (in hex) for main memory address (E201F)16? |
| i ➥ E, 201 |
| ii ➥ F, 201 |
| iii ➥ E, E20 |
| iv ➥ 2, 01F |
Show Answer With Best Explanation
Answer: I
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Cache Memory | Help-Line |
| Q48➡ | GATE 2015 Set-3 Consider the following code sequence having five instructions I1 to I5. Each of these instructions has the following format. OP Ri, Rj, Rkwhere operation OP is performed on contents of registers Rj and Rk and the result is stored in register Ri. I1 : ADD R1, R2, R3Consider the following three statements: S1: There is an anti-dependence between instructions I2 and I5. S2: There is an anti-dependence between instructions I2 and I4. S3: Within an instruction pipeline an anti-dependence always creates one or more stalls.Which one of above statements is/are correct? |
| i ➥ Only S1 is true |
| ii ➥ Only S2 is true |
| iii ➥ Only S1 and S3 are true |
| iv ➥ Only S2 and S3 are true |
Show Answer With Best Explanation
Answer: I
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Microprosessor | Help-Line |
| Q49➡ | GATE 2015 Set-3 Consider the following reservation table for a pipeline having three stages S1, S2 and S3. The minimum average latency (MAL) is _______. |
Show Answer With Best Explanation
Answer: 3
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Pipelining | Help-Line |
| Q50➡ | GATE 2014 Set-1 A machine has a 32-bit architecture, with 1-word long instructions. It has 64 registers, each of which is 32 bits long. It needs to support 45 instructions, which have an immediate operand in addition to two register operands. Assuming that the immediate operand is an unsigned integer, the maximum value of the immediate operand is . |
Show Answer With Best Explanation
Answer: 16383
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Machine-Instructions | Help-Line |
| Q51➡ | GATE 2014 Set-1 Consider a 6-stage instruction pipeline, where all stages are perfectly balanced.Assume that there is no cycle-time overhead of pipelining. When an application is executing on this 6-stage pipeline, the speedup achieved with respect to non-pipelined execution if 25% of the instructions incur 2 pipeline stall cycles is . |
Show Answer With Best Explanation
Answer: 4
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Pipelining | Help-Line |
| Q52➡ | GATE 2014 Set-1 An access sequence of cache block addresses is of length N and contains n unique block addresses. The number of unique block addresses between two consecutive accesses to the same block address is bounded above by k. What is the miss ratio if the access sequence is passed through a cache of associativity A ≥ k exercising least-recently-used replacement policy? |
| i ➥ n/N |
| ii ➥ 1/N |
| iii ➥ 1/A |
| iv ➥ k/n |
Show Answer With Best Explanation
Answer: I
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | cache | Help-Line |
| Q53➡ | GATE 2014 Set-1 Consider two processors P1 and P2 executing the same instruction set. Assume that under identical conditions, for the same input, a program running on P2 takes 25% less time but incurs 20% more CPI (clock cycles per instruction) as compared to the program running on P1. If the clock frequency of P1 is 1GHz, then the clock frequency of P2 (in GHz) is . |
Show Answer With Best Explanation
Answer: 1.6
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | instruction set | Help-Line |
| Q54➡ | GATE 2014 Set-2 A 4-way set-associative cache memory unit with a capacity of 16 KB is built using a block size of 8 words. The word length is 32 bits. The size of the physical address space is 4 GB. The number of bits for the TAG field is |
Show Answer With Best Explanation
Answer: 20
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | cache memory | Help-Line |
| Q55➡ | GATE 2014 Set-2 In designing a computer’s cache system, the cache block (or cache line) size is an important parameter. Which one of the following statements is correct in this context? |
| i ➥ A smaller block size implies better spatial locality |
| ii ➥ A smaller block size implies a smaller cache tag and hence lower cache tag overhead |
| iii ➥ A smaller block size implies a larger cache tag and hence lower cache hit time |
| iv ➥ A smaller block size incurs a lower cache miss penalty |
Show Answer With Best Explanation
Answer: IV
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Cache Memory | Help-Line |
| Q56➡ | GATE 2014 Set-2 If the associativity of a processor cache is doubled while keeping the capacity and block size unchanged, which one of the following is guaranteed to be NOT affected? |
| i ➥ Width of tag comparator |
| ii ➥ Width of set index decoder |
| iii ➥ Width of way selection multiplexor |
| iv ➥ Width of processor to main memory data bus |
Show Answer With Best Explanation
Answer: IV
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Cache Memory | Help-Line |
| Q57➡ | GATE 2014 Set-2 Consider a main memory system that consists of 8 memory modules attached to the system bus, which is one word wide. When a write request is made, the bus is occupied for 100 nanoseconds (ns) by the data, address, and control signals. During the same 100 ns, and for 500 ns thereafter, the addressed memory module executes one cycle accepting and storing the data. The (internal) operation of different memory modules may overlap in time, but only one request can be on the bus at any time. The maximum number of stores (of one word each) that can be initiated in 1 millisecond is |
Show Answer With Best Explanation
Answer: 10000
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Main Memory | Help-Line |
| Q58➡ | GATE 2014 Set-3 Consider the following processors (ns stands for nanoseconds). Assume that the pipeline registers have zero latency. P1: Four-stage pipeline with stage latencies 1 ns, 2 ns, 2 ns, 1 ns. P2: Four-stage pipeline with stage latencies 1 ns, 1.5 ns, 1.5 ns, 1.5 ns. P3: Five-stage pipeline with stage latencies 0.5 ns, 1 ns, 1 ns, 0.6 ns, 1 ns. P4: Five-stage pipeline with stage latencies 0.5 ns, 0.5 ns, 1 ns, 1 ns, 1.1 ns. Which processor has the highest peak clock frequency? |
| i ➥ p1 |
| ii ➥ p2 |
| iii ➥ p3 |
| iv ➥ p4 |
Show Answer With Best Explanation
Answer: III
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Pipelining | Help-Line |
| Q59➡ | GATE 2014 Set-3 An instruction pipeline has five stages, namely, instruction fetch (IF), instruction decode and register fetch (ID/RF), instruction execution (EX), memory access (MEM), and register writeback (WB) with stage latencies 1 ns, 2.2 ns, 2 ns, 1 ns, and 0.75 ns, respectively (ns stands for nanoseconds). To gain in terms of frequency, the designers have decided to split the ID/RF stage into three stages (ID, RF1, RF2) each of latency 2.2/3 ns. Also, the EX stage is split into two stages (EX1, EX2) each of latency 1 ns. The new design has a total of eight pipeline stages. A program has 20% branch instructions which execute in the EX stage and produce the next instruction pointer at the end of the EX stage in the old design and at the end of the EX2 stage in the new design. The IF stage stalls after fetching a branch instruction until the next instruction pointer is computed. All instructions other than the branch instruction have an average CPI of one in both the designs. The execution times of this program on the old and the new design are P and Q nanoseconds, respectively. The value of P/Q is__________________. |
Show Answer With Best Explanation
Answer: 1.50 To 1.60
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Pipelining | Help-Line |
| Q60➡ | GATE 2014 Set-3 The memory access time is 1 nanosecond for a read operation with a hit in cache, 5 nanoseconds for a read operation with a miss in cache, 2 nanoseconds for a write operation with a hit in cache and 10 nanoseconds for a write operation with a miss in cache. Execution of a sequence of instructions involves 100 instruction fetch operations, 60 memory operand read operations and 40 memory operand write operations. The cache hit-ratio is 0.9. The average memory access time (in nanoseconds) in executing the sequence of instructions is . |
Show Answer With Best Explanation
Answer: 1.68
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | cache | Help-Line |
| Q61➡ | GATE 2013 In a k-way set associative cache, the cache is divided into v sets, each of which consists of k lines. The lines of a set are placed in sequence one after another. The lines in set s are sequenced before the lines in set (s+1). The main memory blocks are numbered 0 onwards. The main memory block numbered j must be mapped to any one of the cache lines from |
| i ➥ (j mod v) * k to (j mod v) * k + (k-1) |
| ii ➥ (j mod v) to (j mod v) + (k-1) |
| iii ➥ (j mod k) to (j mod k) + (v-1) |
| iv ➥ (j mod k) * v to (j mod k) * v + (v-1) |
Show Answer With Best Explanation
Answer: I
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Cache Memory | Help-Line |
| Q62➡ | GATE 2013 Consider the following sequence of micro-operations. MBR ← PC MAR ← X PC ← Y Memory ← MBR Which one of the following is a possible operation performed by this sequence? |
| i ➥ Instruction fetch |
| ii ➥ Operand fetch |
| iii ➥ Conditional branch |
| iv ➥ Initiation of interrupt service |
Show Answer With Best Explanation
Answer: IV
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Mirco Operation | Help-Line |
| Q63➡ | GATE 2013 Consider a hard disk with 16 recording surfaces (0-15) having 16384 cylinders (0-16383) and each cylinder contains 64 sectors (0-63). Data storage capacity in each sector is 512 bytes. Data are organized cylinder-wise and the addressing format is . A file of size 42797 KB is stored in the disk and the starting disk location of the file is <1200, 9, 40>. What is the cylinder number of the last sector of the file, if it is stored in a contiguous manner? |
| i ➥ 1281 |
| ii ➥ 1282 |
| iii ➥ 1283 |
| iv ➥ 1284 |
Show Answer With Best Explanation
Answer: IV
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Secondary Memory | Help-Line |
| Q64➡ | GATE 2013 Consider an instruction pipeline with five stages without any branch prediction: Fetch Instruction (FI), Decode Instruction (DI), Fetch Operand (FO), Execute Instruction (EI) and Write Operand (WO). The stage delays for FI, DI, FO, EI and WO are 5 ns, 7 ns, 10 ns, 8 ns and 6 ns, respectively. There are intermediate storage buffers after each stage and the delay of each buffer is 1 ns. A program consisting of 12 instructions I1, I2, I3, I4 …, I12 is executed in this pipelined processor. Instruction I4 is the only branch instruction and its branch target is I9. If the branch is taken during the execution of this program, the time (in ns) needed to complete the program is |
| i ➥ 132 |
| ii ➥ 165 |
| iii ➥ 176 |
| iv ➥ 328 |
Show Answer With Best Explanation
Answer: II
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Pipelining | Help-Line |
| Q65➡ | GATE 2013 A RAM chip has a capacity of 1024 words of 8 bits each (1K×8). The number of 2×4 decoders with enable line needed to construct a 16K×16 RAM from 1K×8 RAM is |
| i ➥ 4 |
| ii ➥ 5 |
| iii ➥ 6 |
| iv ➥ 7 |
Show Answer With Best Explanation
Answer: II
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Cache Memory | Help-Line |
| Q66➡ | GATE 2013 Common Data for Questions 66 and 67 : The following code segment is executed on a processor which allows only register operands in its instructions. Each instruction can have atmost two source operands and one destination operand. Assume that all variables are dead after this code segment. 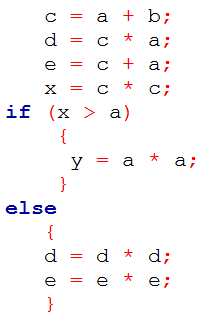 Suppose the instruction set architecture of the processor has only two registers. The only allowed compiler optimization is code motion, which moves statements from one place to another while preserving correctness. What is the minimum number of spills to memory in the compiled code? |

| i ➥ 0 |
| ii ➥ 1 |
| iii ➥ 2 |
| iv ➥ 3 |
Show Answer With Best Explanation
Answer: II
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Code Segment | Help-Line |
| Q67➡ | GATE 2013 Common Data for Questions 66 and 67 : The following code segment is executed on a processor which allows only register operands in its instructions. Each instruction can have atmost two source operands and one destination operand. Assume that all variables are dead after this code segment. What is the minimum number of registers needed in the instruction set architecture of the processor to compile this code segment without any spill to memory? Do not apply any optimization other than optimizing register allocation. |
| i ➥ 3 |
| ii ➥ 4 |
| iii ➥ 5 |
| iv ➥ 6 |
Show Answer With Best Explanation
Answer: II
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Code Segment | Help-Line |
| Q68➡ | GATE 2012 Register renaming is done in pipelined processors |
| i ➥ as an alternative to register allocation at compile time |
| ii ➥ for efficient access to function parameters and local variables |
| iii ➥ to handle certain kinds of hazards |
| iv ➥ as part of address translation |
Show Answer With Best Explanation
Answer: III
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Pipelining | Help-Line |
| Q69➡ | GATE 2012 Statement for Linked Answer Questions 69 and 70: A computer has a 256 KByte, 4-way set associative, write back data cache with block size of 32 Bytes. The processor sends 32 bit addresses to the cache controller. Each cache tag directory entry contains, in addition to address tag, 2 valid bits, 1 modified bit and 1 replacement bit. The number of bits in the tag field of an address is |
| i ➥ 11 |
| ii ➥ 14 |
| iii ➥ 16 |
| iv ➥ 27 |
Show Answer With Best Explanation
Answer: III
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Cache Mapping | Help-Line |
| Q70➡ | GATE 2012 Statement for Linked Answer Questions 69 and 70: A computer has a 256 KByte, 4-way set associative, write back data cache with block size of 32 Bytes. The processor sends 32 bit addresses to the cache controller. Each cache tag directory entry contains, in addition to address tag, 2 valid bits, 1 modified bit and 1 replacement bit. The size of the cache tag directory is |
| i ➥ 160 Kbits |
| ii ➥ 136 Kbits |
| iii ➥ 40 Kbits |
| iv ➥ 32 Kbits |
Show Answer With Best Explanation
Answer: I
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Cache Mapping | Help-Line |
| Q71➡ | GATE 2011 A computer handles several interrupt sources of which the following are relevant for this question. . Interrupt from CPU temperature sensor (raises interrupt if CPU temperature is too high) . Interrupt from Mouse(raises interrupt if the mouse is moved or a button is pressed) . Interrupt from Keyboard(raises interrupt when a key is pressed or released) . Interrupt from Hard Disk(raises interrupt when a disk read is completed) Which one of these will be handled at the HIGHEST priority? |
| i ➥ Interrupt from Hard Dist |
| ii ➥ Interrupt from Mouse |
| iii ➥ Interrupt from Keyboard |
| iv ➥ Interrupt from CPU temperature sensor |
Show Answer With Best Explanation
Answer: IV
Explanation: Upload Soon
| More Discussion | Explanation On YouTube | Interrupt | Help-Line |
| Q72➡ | |